I miss liner notes. In the age of infinite streaming and algorithmic playlists I find myself longing for the days when you’d flip open a CD case and actually read about the music you were listening to. Who produced this? What’s the story behind the album? Why does this track feel different from everything else they’ve made?
Spotify and Apple Music are great at giving you more music. They’re less good at helping you understand why you might love something, or what to explore next. So I built my own solution—and then rebuilt it twice.
The problem I was trying to solve
My relationship with Last.fm goes back to 2007. In case you’re not familiar, Last.fm is a service that “scrobbles” (tracks) everything you listen to, building a comprehensive history of your musical life. It’s become a wonderful archive of my taste evolution over nearly two decades.
Last.fm is great at telling you what you listened to. It’s less useful for helping you understand why you might love something, or what else you should explore. Spotify and Apple Music’s algorithmic playlists are fine, but they often feel like they’re optimizing for engagement rather than genuine discovery.
I wanted a tool that would:
- Show me context about the artists and albums in my listening history
- Help me discover music through similarity and connection, not just popularity metrics
- Give me that “liner notes” depth I was craving
- Work with my existing Last.fm data (18 years of listening history is a lot to throw away)
So I started building, first by copy-pasting from GPT–4 (the olden days!), and most recently with Antigravity + Claude Opus 4.5 (we’ve come a long way since 2023). Here’s where it all stands today…
Listen To More: three iterations and counting
Listen To More is the core project—a music discovery platform that combines real-time listening data with AI-powered insights.
The first version was simple: a personal dashboard that pulled my Last.fm data and displayed it nicely. Functional, but limited. The second version added some AI summaries using OpenAI’s API. Better, but still rough around the edges.
The current version—iteration three—is a complete rebuild focused on speed and multi-user support. What started as “a thing I made for myself” is now something anyone can use. Sign in with your Last.fm account, and you get:
- Rich album and artist pages with AI-generated summaries, complete with source citations (so you know the AI isn’t just making things up)
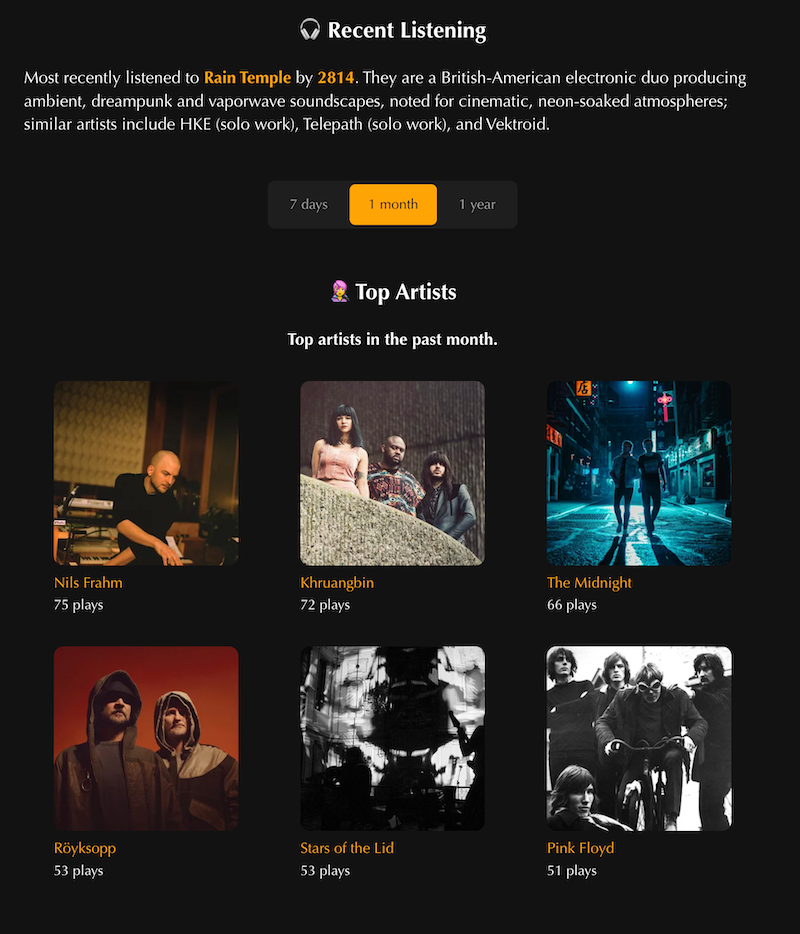
- Your personal stats showing recent listening activity, top artists and albums over different time periods.
- Weekly insights powered by AI that analyze your 7-day listening patterns and suggest albums you might love
- Cross-platform streaming links for every album—Spotify, Apple Music, and more
- A Discord bot so you can share music discoveries with friends
The tech stack is Hono on Cloudflare Workers, with D1 (SQLite) for the database and KV for caching. The whole thing is server-side rendered with vanilla JavaScript for progressive enhancement. Pages load in about 300ms, then AI summaries stream in asynchronously.
I chose this stack partly because I work at Cloudflare and wanted to understand our developer platform better. More on that later.
Extending the ecosystem with MCP servers
MCP stands for Model Context Protocol. In plain terms, it’s a standard that lets AI assistants (like Claude) connect to external data sources and tools. Think of it as giving an AI the ability to actually use personalized data rather than just answer questions based on pre-training.
I built two MCP servers to extend my music discovery ecosystem:
Last.fm MCP Server
Available at lastfm-mcp.com, this server lets AI assistants access your Last.fm listening data. Once connected, you can have conversations like:
- “When did I start listening to Led Zeppelin?”
- “What was I obsessed with in summer 2023?”
- “Show me how my music taste has evolved over the years”
The AI can pull your actual scrobble data, analyze trends, and give you personalized insights. It supports temporal queries (looking at specific time periods), similar artists discovery, and comprehensive listening statistics.
Discogs MCP Server
This one connects to Discogs—the massive music database and marketplace that’s especially popular with vinyl collectors. If you have a Discogs collection, the MCP server lets AI assistants:
- Search your collection with intelligent mood mapping (“find something mellow for a Sunday evening”)
- Get context-aware recommendations based on what you own
- Provide collection analytics and insights
Both servers run on Cloudflare Workers and use OAuth for secure authentication. They’re open source if you want to poke around or deploy your own.
What I learned
I’m a Product Manager, not an engineer. But I’ve found that having more technical depth broadens the scope of things I am able to contextualize—and makes me more confident in my interactions with engineers. Here’s what building these projects reinforced for me:
- Side projects are a low-stakes learning environment. When you’re building for yourself, there’s no pressure to ship by a deadline or meet someone else’s requirements. You can experiment, break things, and iterate freely. I tried approaches that would have been too risky to propose in a work context—some of them broke the site spectacularly, others worked beautifully.
- There’s no substitute for using your own product. I use these tools every day. That constant exposure surfaces issues and opportunities that you’d never catch in a quarterly review or user interview. The feature prioritization becomes obvious when you’re feeling your own friction.
- Building with your company’s tools is invaluable. I now have deep, practical knowledge of Cloudflare Workers, D1, KV, and the rest of our developer platform. When I’m talking to customers or evaluating feature requests, I’m drawing on real experience, not just documentation. I can empathize with the developer experience because I’ve lived it.
- The fun matters. I keep coming back to these projects because I genuinely enjoy working on them. The satisfaction of solving a problem you personally care about is different from the satisfaction of shipping something at work. Both are valuable, but the former is what sustains a side project through the inevitable rough patches.
What’s next
I have a list of features I’d love to add—better recommendations, more sophisticated listening pattern analysis, maybe even integration with other music services. But I’m also learning to pace myself. These projects aren’t going anywhere, and part of the joy is the slow, steady improvement over time.
If you’re curious, you can check them out here:
And if you’re a PM thinking about starting a technical side project: do it. Pick something you personally care about, use tools you want to learn, and give yourself permission to build slowly. The lessons transfer in ways you won’t expect.