Rather than see the agent backlash as a clear sign that AI is a scam, or that it is doomed, it might make more sense to see this development in the context of a normal technological adoption curve. […]
As SemiAnalysis’s Doug O’Laughlin told me in an interview last week, every new technology requires an extended period of trial and error, as organizations toggle between (a) not enough experimentation or spending, followed by (b) too much experimentation and spending, followed by (c) too dramatic a pullback, followed by (d) the repetition of steps (a) through (c), until firms figure out a long-term balance between labor spending and tech spending. Whether AI skeptics like [cognitive scientist Gary] Marcus are right that the bubble is about to pop depends entirely on a question that, as of today, nobody can definitively answer: Is the bill worth it?
Our month-over-month growth rate in Q1 2026 was double our growth rate in Q4 2025. Buttondown has, roughly, grown a little less than 2x every year of its existence; this — its eighth year — is poised to shatter that, if trends hold.
Almost all of that incremental growth, meaning the growth in addition to our historical trend, I attribute to LLMs. We ask people when they sign up what brought them here, and an answer that went from surprising to banal to overwhelming over the course of Q1 was: an LLM. Users of all stripes cite an LLM as the reason that they ended up at Buttondown’s front door.
You should click through for the whole post because he explains why he thinks this happened:
People have asked why I think we have been the beneficiary of this genre of growth. There is one fairly interesting reason: we have accidentally built a very LLM-friendly business in this space.
I’ve always been a big believer in API-first design, and this feels like an almost accidental enormous additional benefit to that approach. Anyway, all that to say… my newsletter is on Buttondown, and yours should be too.
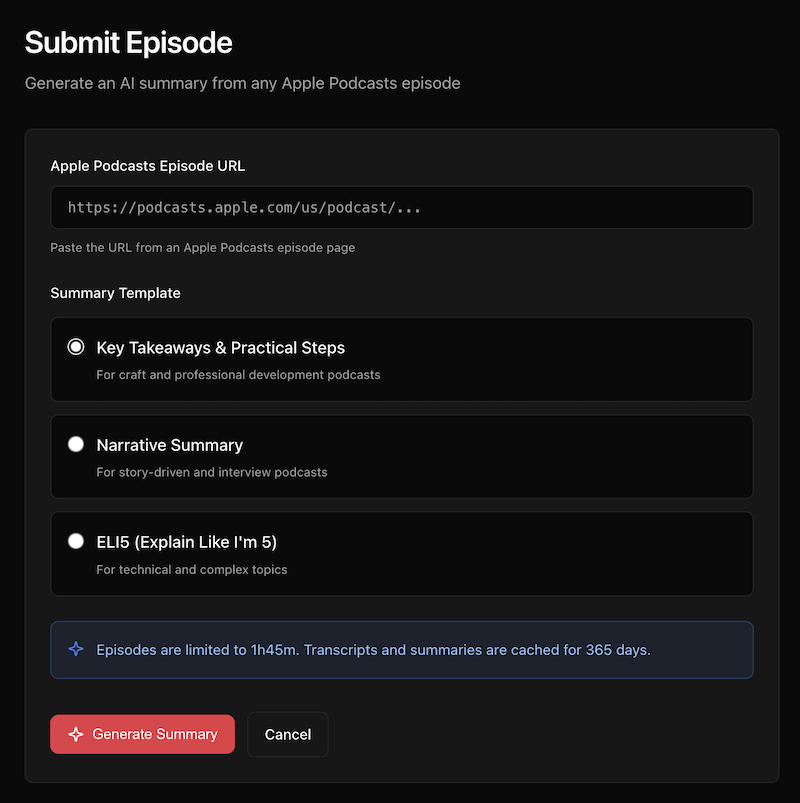
Do you ever listen to a podcast episode and wish you could have a summary you could reference later? Not the whole transcript or someone else’s review, just a concise breakdown of the key points in a format you can scan quickly when you need to remember what was covered. Well, that’s why I spent the weekend building TL;DL (Too Long; Didn’t Listen). It generates AI summaries from podcast episodes.
Beyond that, there were a few other podcast use cases I kept running into:
Catching up on episodes I missed. Sometimes a podcast gets 10 episodes ahead while life happens. A summary helps me decide which ones are worth going back to.
Getting a feel for a new podcast. Before committing to a full episode, I want to know if a new show covers topics in a way that works for how I think and learn.
Quick reference after listening. When I want to apply something from an episode—like a framework or technique—I don’t want to re-listen to an hour of audio to find the relevant 5 minutes.
So I built something for myself, and now I’m making it available to others.
How It Works
Registered users can submit an Apple Podcasts episode URL, choose a summary template, and the system does the rest. It transcribes the audio (using OpenAI Whisper), generates a summary (using GPT–5.2), and caches everything for a year.
The three templates are designed for different types of content:
Key Takeaways & Practical Steps — This is the default, and it’s what I use most. The summary includes an overview, key insights, actionable steps, and notable quotes. Best for professional development and craft podcasts where you want to walk away with something to implement.
Narrative Summary — For story-driven content and interviews. Instead of bullet points, this generates flowing prose that captures the arc of the conversation, including key moments and themes.
ELI5 (Explain Like I’m 5) — For technical or complex topics. It breaks down dense material using everyday analogies and simple language.
The ELI5 Template Passed the Real Test
My wife is a therapist. She listens to highly technical psychology podcasts about things like Transference-Focused Psychotherapy and pathological narcissism. When I ran a recent episode she listed to through TL;DL, she was genuinely impressed by the “Key Takeaways” summary. It captured the clinical nuances accurately.
I, on the other hand, didn’t understand a word of it.
So I generated another summary using the “ELI5” template, and suddenly I could follow along. Concepts like devaluation got explained as “when a patient puts down the therapist, the therapy, or anything connected to it.” The technical frameworks became accessible. Here’s the episode page if you want to toggle between the two summaries yourself.
A Note about Podcast Creators and Attribution
Attribution matters to me. Every episode page prominently displays the podcast name, creator names, and both a “Listen on Apple Podcasts” link and a “Website” link to the official podcast website. My hope is that TL;DL helps expand a podcast’s audience by making the content more accessible. Summaries should bring people to a podcast, not replace the experience of listening—most podcasts have transcripts available already after all.
That said, if creators would rather not have their podcast processed, they can opt out and I’ll add their show to the blocklist.
The Technical Bits
For those interested in the stack: TL;DL runs entirely on Cloudflare’s edge platform. Cloudflare Workers handles the serverless compute, Workers KV stores the cached transcripts and summaries, and Cloudflare Queues manages the background job processing.
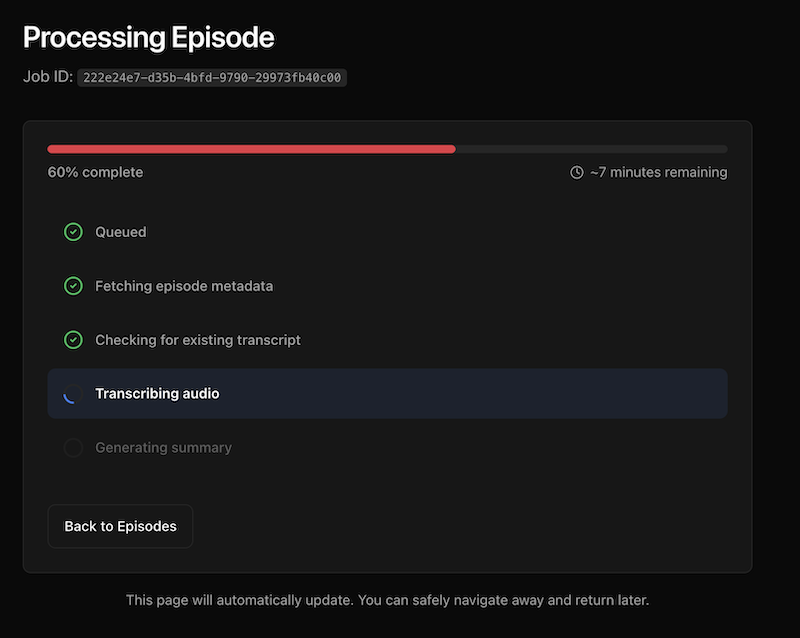
One interesting technical challenge was job status consistency. When you submit an episode, you want to see the status update in real-time as it progresses from “queued” to “transcribing” to “summarizing” to “completed.” Workers KV is eventually consistent, which meant status updates could lag by up to a minute. Users would refresh and still see “queued” even after the job was done.
I solved this with Durable Objects, Cloudflare’s strongly consistent coordination layer. The job status gets written to both the Durable Object (for immediate reads) and KV (for persistence and fallback). The UI now updates instantly.
Audio file handling for long episodes was another challenge. OpenAI Whisper has a 25MB file size limit. For podcasts that exceed this, I implemented MP3 frame-aware chunking—splitting the audio at frame boundaries so transcription can be stitched back together cleanly. The overlap handling ensures no words get lost between chunks.
What’s Next
Beyond solving my own problem, this was one of those projects where the building itself was the reward. The technical challenges were interesting, the product felt useful from day one, and I got to learn Durable Objects properly.
Submitting new episodes is currently invite-only while I iron out the rough edges. If you’re interested in access, reach out. For now, you can browse existing summaries to see how it works.
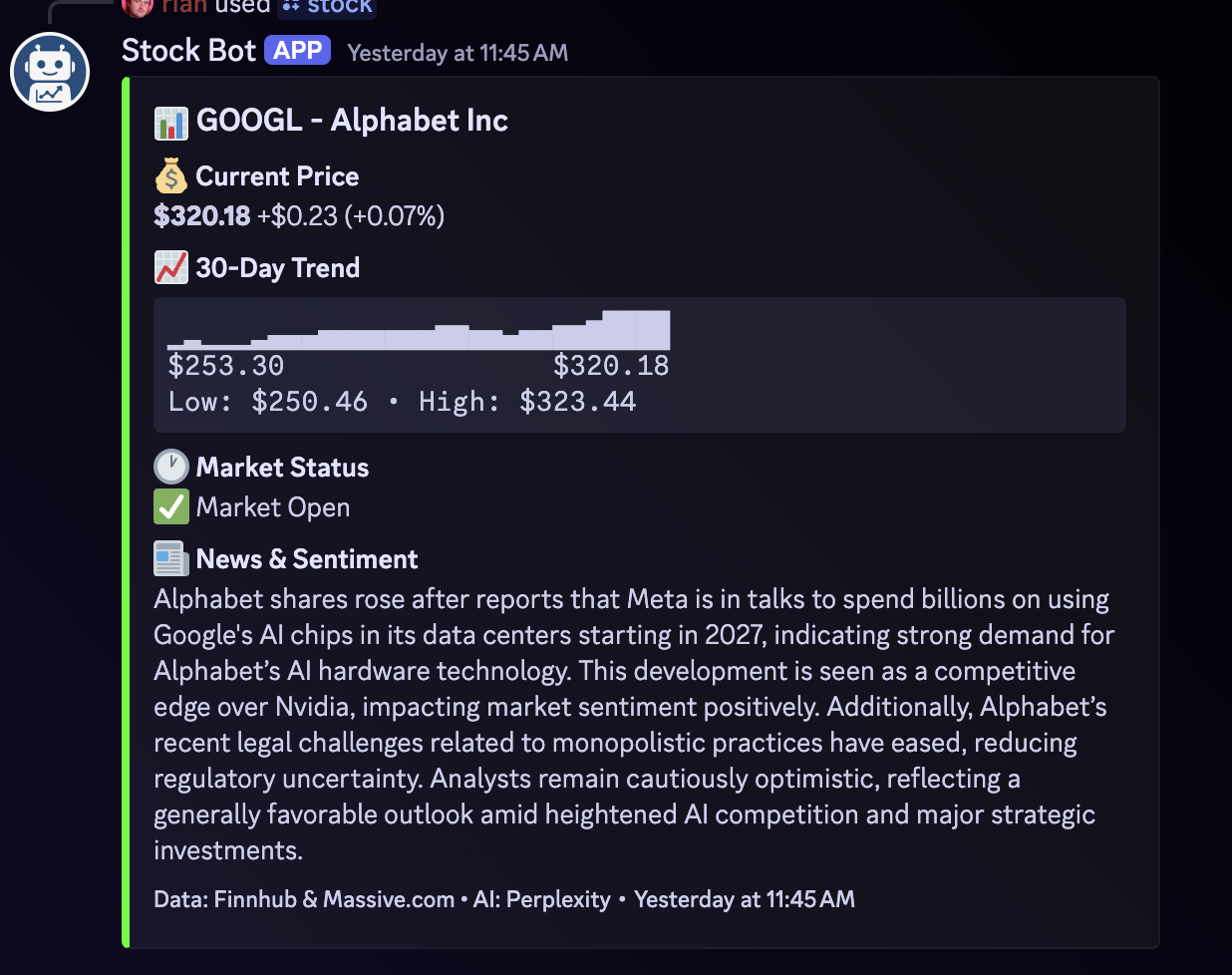
Not sure how many people would be interested in this, but it was fun to make so I thought I’d share. This is a Discord bot that provides real-time stock and cryptocurrency information, 30-day price trends, and AI-powered news summaries through slash commands. When you add the bot to Discord you can use the /stock and /crypto commands to get information like this:
This is an essay I think everyone should read, front to back. It’s about all the things we are living through right now, but it’s especially about work (and AI):
I’m not sure hiring can ever be much more efficient, because neither side has reason to show themselves as they really are, warts and all. Idealistically, both would come straight; pragmatically, it is a game of chicken. Candidates polish résumés and present curated versions of their abilities, listing outcomes and impact statistics with dubious accuracy and provenance. Companies do the same, putting culture and mission front and center while hiding systematic dysfunctions and looming existential risks. When neither side is forthcoming, you’re left with proxies: a famous logo on a resume, a polished culture deck.
Well, today I learned about the consequences of population decline:
The U.S. cannot grow through native-born fertility alone. As immigration collapses, the US population will stagnate and even shrink. Urban economics will buckle. Fields will go unharvested. Homes will go unbuilt. Sick Americans will go untreated. Life-saving medicines will go undiscovered. Many voters hated the era of record immigration. They might hate the era of record deportations even more.
Yes I know this sounds dire. But read the whole essay, Derek brings receipts.
This take on the Pocket shutdown resonates with me real hard:
“What began as a read-it-later app”, they assert, “evolved into something much bigger.” That was the whole problem: the mistake that led ultimately to this “difficult decision” by Mozilla. Pocket was a good tool. Its integration with Kobo, another excellent tool, made it that much more valuable to users like me. We didn’t need “something much bigger”. But by trying to turn Pocket into something much bigger, Mozilla actually killed it.
This is the core of the disappointment that many of us feel with the Sparrow acquisition. It’s not about the $15 or less we spent on the apps. It’s not about the team’s well-deserved payout. It’s about the loss of faith in a philosophy that we thought was a sustainable way to ensure a healthy future for independent software development, where most innovation happens.
The key to any successful B2B Product-Led Growth (PLG) strategy lies in connecting end-user adoption to enterprise-level deals. But because B2B PLG often looks like, smells like, and acts like consumer product, it pulls product and marketing teams into a deadly gravitation pull of crafting consumer-like experiences focused solely on the individual value. While acquiring individual users is a natural first step, failing to consider the dire need to connect that individual to a team and a company level value WILL sabotage your future growth.
So, to sum up, we won because we started at the right time and we had taste. We were there when a new paradigm was being born and we approached the problem of helping people embrace that new paradigm with a developer experience centric approach that nobody else had the capacity for or interest in.
The whole post is worth reading for the history and all ways things just went right for GitHub.
My favorite positioning quote is from Dolly Parton, who said, “Find out what you are and do it on purpose.” A great positioning exercise is a structured process that allows a team to get real clarity on exactly “what you are” so marketing and sales can “do it on purpose.”
Come to her article for the Dolly Parton quote, stay for the Beyoncé positioning lesson…